
Interpretability in AI: Concepts, Methods, and Applications

Interpretability in AI: Concepts, Methods, and Applications
TLDR
This paper explains why it's important for AI models to be understandable (interpretable). It discusses different ways to achieve interpretability and its benefits for building trust, fairness, and improving AI systems.
Abstract
Interpretability in artificial intelligence (AI) refers to the extent to which a human can comprehend the rationale behind a machine learning model's decision. This paper offers a comprehensive overview of the significance of interpretability, explores current methodologies, examines applications across various domains, and outlines future directions. We emphasize the critical need for interpretable models, especially in high-stakes fields such as healthcare and finance, and discuss the inherent trade-offs between model accuracy and interpretability. The paper aims to advance the discourse on creating more transparent and accountable AI systems, thereby fostering trust, ensuring fairness, and enhancing the overall reliability and efficacy of AI applications.
Introduction
Artificial Intelligence (AI) has become an integral part of modern society, driving innovations and efficiencies across a wide range of industries. From healthcare and finance to transportation and entertainment, AI systems are increasingly used to make critical decisions that affect human lives. However, many of these AI systems, especially those based on complex machine learning algorithms like deep learning, operate as "black boxes," offering little insight into how they reach their conclusions. This opacity can lead to a lack of trust, accountability, and ethical concerns.
Importance of Interpretability
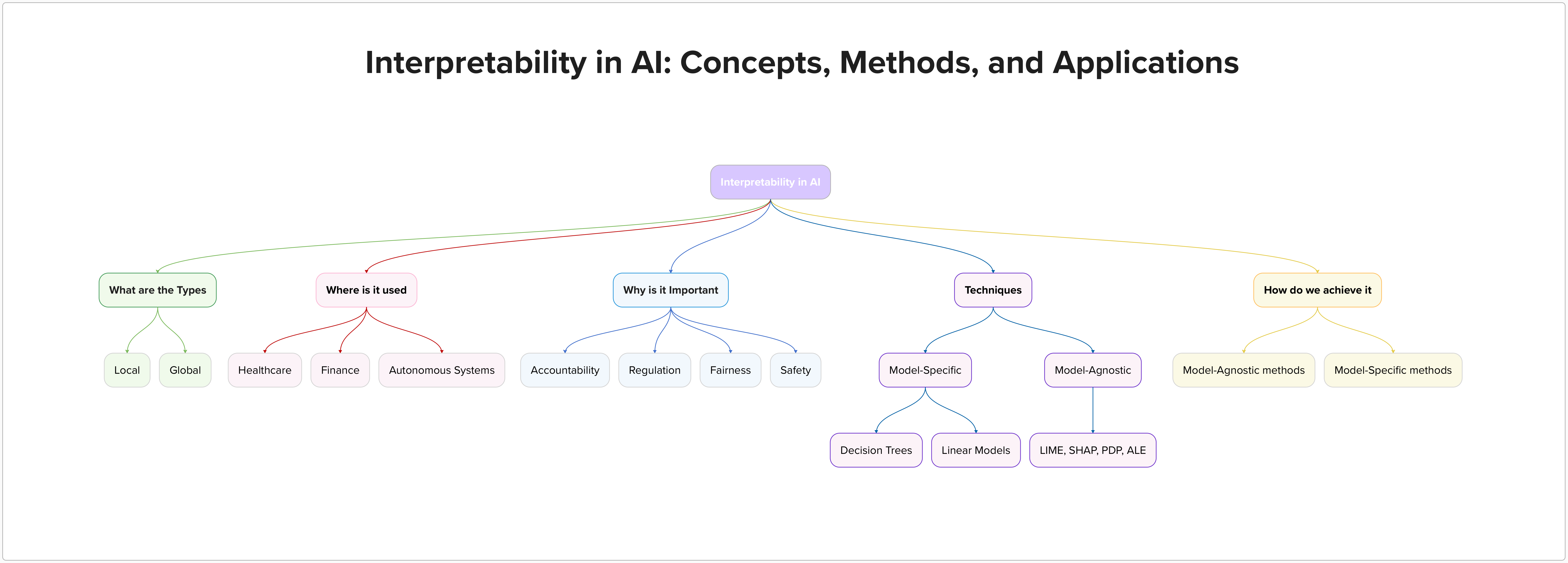
Interpretability is the degree to which a human can understand the cause of a decision made by an AI system. It is essential for several reasons:
Trust: Users are more likely to trust and adopt AI systems if they understand how decisions are made.
Accountability: In high-stakes domains such as healthcare, finance, and criminal justice, it is crucial to hold AI systems accountable for their decisions.
Ethical Considerations: Ensuring that AI systems make fair and unbiased decisions requires transparency in how these decisions are made.
Regulatory Compliance: Legal frameworks, such as the European Union's General Data Protection Regulation (GDPR), mandate that individuals have the right to explanations of automated decisions that significantly affect them.
Objective
This paper aims to provide a detailed survey of the current need of interpretability in AI, covering various methods, applications, challenges, and future directions. By doing so, we hope to contribute to the ongoing discourse on making AI systems more transparent and accountable.
Theoretical Foundations
Definition of Interpretability
Interpretability in the context of AI refers to the ability to explain or to present in understandable terms to a human the inner workings of a model or the cause of its decisions. Interpretability is often contrasted with explainability, though the terms are sometimes used interchangeably.
Types of Interpretability
Global Interpretability
Global interpretability involves understanding the overall behavior of a model. This means being able to comprehend how the model processes inputs and generates outputs across a wide range of scenarios. Global interpretability is crucial for assessing the general principles by which a model operates.
Local Interpretability
Local interpretability focuses on understanding individual predictions. This involves explaining why a model made a specific decision for a particular instance. Local interpretability is particularly important for debugging models and for providing insights into specific cases that require human intervention.
Intrinsic vs. Post-hoc Interpretability
Intrinsic Interpretability
Intrinsic interpretability refers to models that are inherently interpretable due to their simple and transparent structure. Examples include decision trees, linear regression models, and rule-based systems. These models are designed to be interpretable from the ground up.
Post-hoc Interpretability
Post-hoc interpretability involves applying techniques to explain the decisions of a model after it has been trained. These techniques can be used with complex models like neural networks and ensemble methods that are not inherently interpretable. Examples include Local Interpretable Model-agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP).
Interpretability Techniques
Model-Specific Methods
Decision Trees and Rule-Based Models
Decision trees and rule-based models are examples of intrinsically interpretable models. Decision trees split the data into subsets based on feature values, creating a tree-like model of decisions. Rule-based models use if-then rules to make predictions. Both of these methods are straightforward to interpret because they provide clear decision paths from input features to output predictions.
Linear Models and Generalized Linear Models
Linear models, such as linear regression and logistic regression, are interpretable because they provide a direct relationship between input features and the predicted outcome. Coefficients in these models indicate the strength and direction of the relationship between each feature and the outcome. Generalized linear models extend linear models to handle a wider range of response variable distributions, maintaining interpretability through their linear predictors.
Model-Agnostic Methods
Local Interpretable Model-agnostic Explanations (LIME)
LIME is a technique that approximates the complex model locally with a simpler, interpretable model. For a given prediction, LIME generates a perturbed dataset and uses it to fit an interpretable model, such as a linear model or decision tree, that mimics the complex model’s behavior in the local region around the prediction. This allows users to understand why the complex model made a specific decision.
SHapley Additive exPlanations (SHAP)
SHAP values, derived from cooperative game theory, provide a unified measure of feature importance for individual predictions. SHAP values explain the contribution of each feature to the difference between the actual prediction and the average prediction. This method provides a consistent and theoretically sound approach to local interpretability.
Partial Dependence Plots (PDP)
Partial Dependence Plots (PDP) illustrate the relationship between a selected feature and the predicted outcome, averaging out the effects of other features. PDPs help in understanding how changes in a feature affect the model’s predictions across the entire dataset.
Accumulated Local Effects (ALE)
Accumulated Local Effects (ALE) plots address some limitations of PDPs by considering the feature distribution. ALE plots show how a feature influences the prediction on average in a local neighborhood, providing a more accurate and unbiased interpretation.
Applications of Interpretability
Healthcare
Case Study: Interpretable Models in Diagnosing Diseases
Interpretable AI models are increasingly used in healthcare for diagnosing diseases. For example, interpretable models can help predict patient outcomes based on medical history, lab results, and imaging data. A specific case study involves using decision trees to diagnose diabetes. These models provide clear decision rules that healthcare professionals can understand and trust.
Benefits
Trust: Interpretable models enhance trust among healthcare professionals and patients, as the decision-making process is transparent.
Actionability: Clear explanations enable healthcare professionals to take appropriate actions based on model predictions.
Finance
Case Study: Risk Assessment and Credit Scoring
In the financial sector, interpretable models are used for risk assessment and credit scoring. For instance, logistic regression models are commonly employed to predict the likelihood of loan default. These models provide clear coefficients that indicate the influence of each feature, such as income and credit history, on the prediction.
Benefits
Regulatory Compliance: Interpretable models help financial institutions comply with regulations that require explanations for automated decisions.
Transparency: Clear explanations enhance transparency, allowing customers to understand the reasons behind their credit scores.
Autonomous Systems
Case Study: Interpretability in Self-Driving Cars
In autonomous systems like self-driving cars, interpretability is critical for safety and public acceptance. Techniques like LIME and SHAP can be used to explain the decisions of deep learning models used in object detection and navigation.
Benefits
Safety: Understanding model decisions helps identify and mitigate potential safety risks.
Public Acceptance: Transparent decision-making processes increase public trust in autonomous systems.
Legal and Ethical Considerations
Fairness and Bias
Interpretable models play a crucial role in identifying and mitigating biases in AI systems. For example, interpretable techniques can reveal if a model is unfairly biased against certain demographic groups, enabling developers to address these issues.
Accountability
Interpretable models ensure accountability by providing clear explanations for decisions. This is particularly important in high-stakes domains where automated decisions can have significant consequences.
Challenges and Trade-offs
Accuracy vs. Interpretability
One of the primary challenges in interpretability is the trade-off between accuracy and interpretability. Complex models like deep neural networks often achieve higher accuracy but are less interpretable. Conversely, simpler models like decision trees are more interpretable but may sacrifice some accuracy.
Complexity of Interpretability Methods
Some interpretability techniques, particularly post-hoc methods like SHAP, can be computationally intensive and complex to implement. This complexity can pose challenges in practical applications, especially in real-time systems.
Subjectivity
Interpretability is inherently subjective, as different stakeholders may have varying definitions and requirements for what constitutes an interpretable model. For instance, a data scientist may prioritize detailed technical explanations, while an end-user may prefer simpler, high-level summaries.
Scalability
Applying interpretability techniques to large-scale models can be challenging. As the complexity and size of models increase, ensuring that interpretability methods remain effective and efficient becomes more difficult.
Future Directions
Advancements in Interpretable Models
The future of AI interpretability lies in the development of models that inherently balance performance with interpretability. Researchers are exploring hybrid models that combine the simplicity of interpretable models with the power of complex algorithms. For instance, attention mechanisms in neural networks can highlight which parts of the input are most influential in making a decision, thus offering a layer of interpretability within otherwise opaque models.
Another promising direction is the development of inherently interpretable models that maintain competitive performance levels. Examples include generalized additive models (GAMs) and monotonic neural networks, which restrict the model structure to ensure that it remains interpretable while retaining high predictive power.
Automated Interpretability
Advancements in automated machine learning (AutoML) are paving the way for automated interpretability. AutoML systems can now include interpretability as a criterion during the model selection process, ensuring that the chosen model is not only accurate but also interpretable. This approach can democratize AI by making it easier for non-experts to develop and understand machine learning models.
Automated interpretability tools can also dynamically generate explanations tailored to different types of users. For example, a medical professional might receive a detailed explanation of a model's prediction, while a patient might receive a simplified, high-level summary.
User-Centric Interpretability
Interpretability is not one-size-fits-all. Different users, such as data scientists, domain experts, and laypeople, have varying needs and levels of expertise. Future research is focusing on developing user-centric interpretability tools that provide explanations tailored to the specific needs of different user groups.
For instance, interactive visualizations can help data scientists explore model behavior in detail, while narrative explanations can help laypeople understand the outcomes of complex models. User studies and human-computer interaction (HCI) research are essential for understanding how different users perceive and utilize explanations, leading to more effective interpretability tools.
Integrating Interpretability into the AI Development Lifecycle
Interpretability should be considered throughout the entire AI development lifecycle, from data collection and preprocessing to model deployment and monitoring. By embedding interpretability into every stage, developers can ensure that AI systems remain transparent and accountable.
Data Collection and Preprocessing
Ensuring that the data used to train AI models is transparent and well-understood is the first step towards interpretability. Clear documentation of data sources, preprocessing steps, and feature engineering processes can help stakeholders understand the foundation on which models are built.
Model Training and Evaluation
During model training, developers can use interpretable algorithms or incorporate interpretability constraints into complex models. Evaluation metrics should include not only accuracy and performance but also measures of interpretability, such as feature importance scores and the stability of explanations.
Deployment and Monitoring
Once models are deployed, ongoing monitoring is crucial to ensure they continue to operate transparently and fairly. Automated tools can generate explanations for real-time predictions, allowing users to understand and trust AI decisions. Additionally, continuous monitoring can help detect and mitigate any biases or drifts in model behavior.
The Need for Interpretability
The need for interpretability in AI cannot be overstated. As AI systems become more prevalent and powerful, the ability to understand and trust these systems is paramount. Interpretability not only enhances transparency and accountability but also ensures that AI systems are used ethically and responsibly.
The pursuit of interpretability in AI is inherently interdisciplinary, drawing upon insights and methodologies from various fields beyond computer science and machine learning. By incorporating perspectives from disciplines such as cognitive science, human-computer interaction (HCI), and ethics, we can develop a more holistic understanding of interpretability and its implications for human-AI interaction.
Cognitive Science: Cognitive science offers valuable insights into human reasoning, decision-making, and information processing. By leveraging theories and findings from cognitive science, we can design interpretability techniques that align with how humans perceive, understand, and interact with explanations. For example, research on mental models and analogical reasoning can inform the development of interpretable AI systems that provide explanations that resonate with human intuition and cognition.
Human-Computer Interaction (HCI): The field of HCI focuses on the design, evaluation, and implementation of interactive computing systems for human use. HCI principles and methodologies can significantly contribute to the development of user-centric interpretability tools that effectively communicate AI decisions to diverse stakeholders. User studies, usability testing, and design principles from HCI can ensure that interpretability techniques are intuitive, accessible, and tailored to the specific needs and expertise levels of different user groups.
Ethics: As AI systems become increasingly integrated into decision-making processes that can profoundly impact human lives, ethical considerations become paramount. Interpretability plays a crucial role in ensuring the ethical development and deployment of AI systems by promoting transparency, accountability, and fairness. Collaborating with ethicists and incorporating ethical frameworks can help address issues such as algorithmic bias, privacy concerns, and the responsible use of AI in high-stakes domains.
Call to Action
Researchers, practitioners, and policymakers must prioritize interpretability in AI development. By investing in the development of interpretable models, automated interpretability tools, and user-centric explanation methods, we can create AI systems that are both powerful and transparent. Collaborative efforts across disciplines, including AI, HCI, ethics, and law, are necessary to address the complex challenges of interpretability and to ensure that AI serves the best interests of society.
In conclusion, interpretability is a cornerstone of trustworthy AI. By making AI systems more understandable, we can harness their full potential while ensuring they are used responsibly and ethically. The ongoing advancements in interpretability techniques and tools will play a crucial role in shaping the future of AI, making it more transparent, fair, and accountable.
Simple Breakdown of Interpretability in AI:
Imagine a magic box that makes decisions based on data you feed it. This is kind of how AI works. But the problem is, the box often doesn't explain why it makes certain choices. This is where interpretability comes in.
Interpretability is like having a see-through magic box. You can see how the data flows inside and why the box makes the decisions it does. This is important for a few reasons:
Trust: If you don't understand why the box makes a decision, how can you trust it, especially for important things like healthcare or finance?
Fairness: Is the box biased against certain people? Interpretability helps us check for and fix any unfairness.
Understanding: Knowing how the box works helps us improve it and use it better.
The paper talks about different ways to make AI models more interpretable. Some models are built to be clear from the start (like simple decision trees). For more complex models, we can use tools to explain their decisions after they're trained (like LIME or SHAP).